Good Design, part IV: The Role of Tests
We’ve seen how refactoring becomes the primary design activity on an Agile team. Diligent, confident refactoring is possible to the degree that the code is tested through an automated test suite. If the tests don’t cover a portion of the code, a defect may be introduced when that code is altered. If the tests are slow, they’ll run less frequently, and the time between the introduction of a defect and the detection of that defect is slowed.
For example, on my 2002 project, we had about 20,000 tests after the first year. They all ran within 15 minutes; the time it took to walk down to the nearby cafe for a latte. So anyone could make any change necessary and know within 15 minutes whether they had broken something critical. (Aside: In 30 years I’ve never had reason to write non-critical code. I’m not even sure what “non-critical code” means.)
During a refactoring, of course, that’s even too slow. We can’t make a small change then wait 15 minutes, make another small change…
We’d usually select a subset of the full suite that covered as much of the code that we believed would be affected by the refactoring. At most 40 seconds worth of tests. But before pushing that code to the repository, we’d run the full 15-minute suite, just to be sure.
My 2002 project is apparently still running, with frequent modifications being made. They now have over 30,000 tests, all running within 15 minutes. Apparently the last time a developer had to work an evening or weekend to fix a critical defect was 2004. Let’s see…that’s 14 years without an OT show-stopper. Wow!
How do you get there? A number of test-related practices come to mind. First, we have to acknowledge that using end-to-end whole-system tests won’t work. They would take far too long. A key to building a very fast yet comprehensive test suite is to use test doubles. When I test A, if there’s an interaction between A and B, I want the test to have control over B’s responses to A. That’s done either by instantiating the right value of B, or using a mock/fake/stub B…a test double of B.
Test doubles help in testing in a number of ways. The most important is that they allow the majority of tests to run all in memory (“in proc”); not accessing any filesystem, database, or network. Also, since we can use test-doubles to replace any third-party dependencies or parts of the runtime environment (e.g., the system clock), we can create tests that are repeatable.
Another practice is unit-testing. By this I mean testing a single behavior, in isolation. This typically means we’re testing a single function or object in a single, very brief scenario. We do end up with a lot more tests, but they have pinpoint accuracy when something goes wrong, and they’re actually very easy to write, and read. Since we’re on the topic of design: A well-designed test looks a bit different from most well designed code: It’s a clear, readable, straightforward script, with three parts: Given/When/Then, also known as Arrange/Act/Assert. If you’ve ever used use-cases, you’ll recognize pre-conditions, actions, and post-conditions.
You may have tried unit-testing before. Most developers hate it, and I get that. The fun part (writing the code) is done; if one fails you have to figure out if the test or the code is wrong, then fix that; and you have to read through your code and write a test for each possible code-path. And that last one isn’t always easy. In fact, this is often a reflection of the code’s design: The more code-paths live between a single set of curly-braces, the harder it will be to test.
Technically speaking, when you write the tests after the code, you’re really doing what’s called “characterization testing”: You’re capturing the existing behaviors in a test, right or wrong. (Yes, I’ve seen developers convince themselves that they’ll just adjust the tests to match what the code tells them is working.) Characterization testing is actually a very powerful way to cover uncovered code and bolster the test-suite, so that refactorings can be done more quickly and safely.
But there’s another way. What if we wrote the test first? This seems weird at first, but it’s quite natural, actually. I know I need to make my code do something new. I typically have a pretty good idea of exactly what code I need to write in order to have it perform that new behavior. What if I specify that, given certain conditions and inputs, when I invoke this function, then I should get these side-effects or return values? Given, when, then! The test will let me know when I’ve coded the solution correctly, and will remain as a test, which protects my investment in that code.
I build this fine-grained, comprehensive safety-net of tests over time, as the primary way that I write code. This is what’s known as test-first, or Test-Driven Development. As you may notice, it’s really more of a coding tool than a testing technique. In fact, the engineering specification I write in order to earn a new change to the code, really isn’t a test until it passes. Then, it remains as a solid little test for everyone on the team.
Other Agile team practices also have impact on (and are impacted by) design:

Pair Programming
Have you ever written some code (alone), and returned to it six months later, and wondered at what it does? Yeah, I’ve found that whenever I try to code alone, my code seems clever and brilliant to only one person (moi), and only at that moment. With pair programming, a pair of developers naturally designs code that is comprehensible to more than one person. Typically, it makes sense to all the developers on the team.
Note: How do we know it makes sense to the others on the team? Nope, not during a code review. I stopped doing code reviews in 1998. They’ll see it next time they pair with someone else on that area of code, or after they pull the latest changes from the repository. Because, the team is also doing…
Continuous Integration
This is the practice of, well, integrating continuously!
Each time we write code, we do it so it’s tested, designed well, and potentially deployable. Once we have completed a short task, or a related portion of the new feature (or “user story”), we immediately push it to the repository in such a way that the other folks on our team will need to take our changes into their view of the code (their local branch). And that’s where this practice facilitates design: We communicate our design intent, and provide the objects and functions that the rest of the team may need. It avoids the creation of a lot of duplication.
It is a team-communication practice.
Without this practice, the team will have multiple branches, and won’t be sharing their solutions with the other branches in a timely manner. The same is true for refactorings: If I perform a significant refactoring on a branch, others on my team will not immediately benefit from the refactoring. Instead, once I merge my branch, they’ll have to figure out where their branch’s changes are now supposed to go, post-refactoring. Chaos ensues. So, by pushing to a branch shared by the whole team (e.g., “master”) we’re sharing our design choices, and further facilitating frequent, diligent, confident refactorings.
On the teams I worked on, pairs of developers typically pushed changes two or more times per day. With just three pairs, that’s six or more release-ready changes per day, and the next day we’d all start with the exact same code. Also, QA/testers can pull from the repo at any time, to perform Exploratory Testing on the latest build.
CRC Cards
This is an honorary member of my set of Agile Engineering Practices (aka Scrum Developer Practices). Often when teams are starting out with a TDD practice, they are understandably unsure of where to start. “If there’s no code, what am I testing?”
In the Agile world, we avoid doing Big Up-Front Design. And, with refactoring, we’re essentially designing after coding and testing. We talk a lot about incremental design or emergent design. These are all great, but sometimes we need a little kick-start, particularly when building something entirely new. Enter “minimal up-front design.”
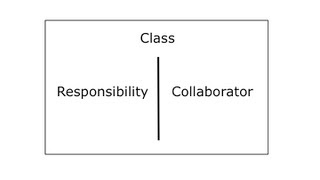
CRC stands for Class, Responsibility, and Collaborator. We actually use index cards, and as we uncover the need for a class, we take a card and write the name of the object we’ve just identified. Responsibilities—effectively the services of the class—get written on a column on the left. When we identify the need for another object that collaborates with this one, we get another card for it, and we also write the name of the collaborator on in the right column of the first card.
It’s a lot like UML, except we resist the temptation to keep the cards or to keep them in-synch with the code. They’re a brainstorming-facilitation technique. A pair or team can “role-play” a scenario, walking through the cards to see if the rough order of delegation makes sense, and is sufficient to complete the task at hand. For some reason teams find it easier to design smaller, more cohesive objects when they use cards rather than code, or a drawing tool.
The end result is a collection of objects that could potentially be built in parallel by different pairs. The services listed on the left are the behaviors that require testing, and the objects in the right column can be stubbed or mocked.
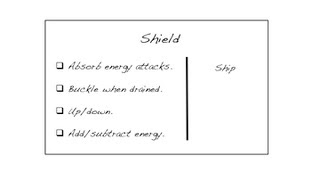
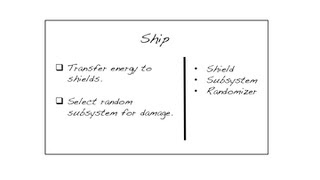
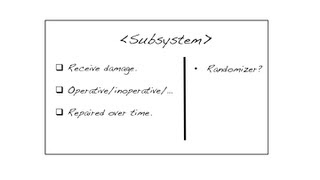
Developers often ask me, “but wouldn’t that result in a lot of merge conflicts?” Can you spin your chair around and ask the other pair “Are you calling that method ‘GetFoo,’ or property ‘Foo’?” Conversation reduces merge conflicts.
Which brings me to my last Agile team practice that greatly impacts the quality of a software design:
Sit Together
Optimally, sit around a table with multiple workstations. No cube walls, no elevators, walls, or state boundaries separating you from your teammates. Keep brain-healthy snacks nearby.

Optimally. If you cannot get that, try to mimic it as much as possible. Keep a constant Google Hangout or Zoom going, for example, even when you’re not talking to each other.
Summary
In part 1, I gave you my definition of a good design: A good design is one that is easy for the team to understand and maintain.
A good software design facilitates future changes. Again, I recommend the team start with Kent Beck’s Four Rules of Simple Design:
- It works! It has tests, and they all pass.
- It’s understandable: The code is expressive, concise, and obvious to the team.
- Once and only once: Behaviors, concepts, and configuration details are defined in one location in the system (code, build scripts, config files). Don’t Repeat Yourself (DRY).
- Minimal: Nothing extra. Nothing designed for some as-yet-unforeseen future need. You Aren’t Going to Need It (YAGNI)
After that, all other lessons of good design will be helpful, and will be easier to absorb because of those four: Design Patterns, S.O.L.I.D. Principles, and similar bodies of experience hold awesome nuggets of software design gold.
And don’t worry if you’re not an expert in one of those “software wisdom traditions.” There’s far too much for any one person to learn. Trust your team. And perhaps think of improving software design as an ongoing, career-spanning adventure!
Responses